
La prueba de Chow o contraste de Chow es una prueba estadística destinada a contrastar la igualdad de los coeficientes de regresión en dos grupos de datos. De esta forma, se utiliza para decidir si ha existido un cambio estructural al pasar de un conjunto de datos al otro. La prueba fue originalmente diseñada por el econometra Gregory Chow in 1960.
Desigualdad de Markov
Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /var/www/html/sigmapedia/wp-content/plugins/latex/latex.php on line 47
Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /var/www/html/sigmapedia/wp-content/plugins/latex/latex.php on line 49
Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /var/www/html/sigmapedia/wp-content/plugins/latex/latex.php on line 47
Warning: preg_replace(): The /e modifier is no longer supported, use preg_replace_callback instead in /var/www/html/sigmapedia/wp-content/plugins/latex/latex.php on line 49
La desigualdad de Markov es una desigualdad probabilística que permite conociendo únicamente la esperanza matemática o media de una distribución acotar la probabilidad del extremo superior de una variable aleatoria no negativa. Más concretamente, para $X \geq 0$ (variable aleatoria no negativa) y el extremo de la distribución $X \geq a$, siendo $a>0$:
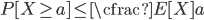
Por ejemplo si conocemos que la calificación media para un examen es de media 6, podemos aproximar o acotar la probabilidad de que la variable aleatoria tome un valor igual o superior a 8 de esta forma:
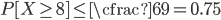
Es decir, gracias a la desigualdad de Markov podemos asegurar que la probabilidad de que una persona obtenga una calificación superior o igual a 8 es inferior o igual a 0.75. Como puede verse, la desigualdad de Markov no proporciona una cota fina de la probabilidad, y es que la probabilidad real puede ser tanto 0.75 como 0.01, valores harto diferentes. Para aproximaciones o cotas más exactas puede utilizarse la desigualdad de Chebyshev, pero esta exige conocer también la desviación típica de la distribucion. El hecho de que la distribución de Chebyshev aporte una cota más exacta es lógico, ya que incorpora la información adicional proporcionada por la desviación.
A pesar de llevar el nombre de Andrey Markov (1856-1922), la desigualdad era conocida ya por su profesor Pafnuty Chebyshev (1821-1853). De hecho, la desigualdad de Chebyshev se demuestra utilizando la desigualdad de Markov, y aquella fue demostrada antes del nacimiento de Markov.
Recorrido intercuartílico
Recorrido o rango intercuartílico o intercuartil es la diferencia entre el tercer y el primer cuartil de una distribución estadística. Se denomina habitualmente con las siglas IQR (InterQuartile Range):
![\[IQR=Q_3-Q_1\]](https://sigmalitika.hirusta.io/wp-content/ql-cache/quicklatex.com-0266a124a2a006acd745dbdf1c3194f7_l3.png "Rendered by QuickLaTeX.com")
De esta forma, el recorrido intercuartílico comprende el recorrido del 50% de los datos centrales de una distribución, dejando en cada extremo un 25% de datos. Se utiliza fundamentalmente como medida de dispersión absoluta: a mayor recorrido intercuartílico, mayor dispersión de los datos, al menos en lo que se refiere a la zona central de la distribución. La ventaja que presenta el recorrido intercuartílico frente recorrido o rango (absoluto) de una distribución es su robustez frente a la presencia de valores atípicos, al estar estos situados en los extremos de la distribución, como es lógico.
El recorrido intercuartílico se utiliza por otra lado en la construcción del diagrama caja o boxplot, coincidiendo la amplitud de la caja del diagrama con el recorrido intercuartílico. Cuanto más amplia es la caja, es decir el recorrido intercuartílico, mayor es la dispersión absoluta de la distribución.
Para una distribución normal estándar, el primer y tercer cuartil son respectivamente -0.67 y 0.67, de modo que el recorrido intercuartílico es 1.34. De esta forma, en general para cualquier distribución normal, el recorrido intercuartílico es:
![\[IQR=1.349 \sigma\]](https://sigmalitika.hirusta.io/wp-content/ql-cache/quicklatex.com-467ed3c641c1f273d34234780c2e2742_l3.png "Rendered by QuickLaTeX.com")
Esta relación entre el recorrido y la desviación en una distribución normal puede utilizarse como criterio de normalidad. Si calculados el recorrido y la desviación (multiplicada por 1.349), ambos difieren significativamente, puede concluirse que la distribución normal no es un modelo ajustado a los datos.
Winsorización
La winsorización es el proceso por el que se sustituye un porcentaje dado de valores extremos en una distribución por lo valores inmediatamente contiguos, con el objetivo de limitar la influencia de estos valores extremos en los estadísticos que resulten de la muestra (consulta el artículo sobre media winsorizada). En ultima instancia, la winsorización implica una censura de datos, que sustituye los valores inferiores o superiores a un valor concreto por dicho valor (por ejemplo cuando se supone que la edad a la muerte de las personas mayores de 100 años es exactamente 100 años).
Media winsorizada
Una media winsorizada es aquella que sustituye un porcentaje dado de datos en cada extremo de la distribución, transformándolos al valor inmediatamente anterior y posterior de los extremos inferior y superior respectivamente. Por ejemplo, si los datos son 4-20-22-24-26-28-30-32-34-36, la media winsorizada al 10% sustituye los datos 4 y 36, por 20 y 34; de esta forma la media winsorizada es 27, mientras que la media aritmética simple. Como se puede comprobar en el ejemplo anterior, la media winsorizada es especialmente adecuada en el caso de la existencia de datos atípicos, cuya influencia mitiga considerablemente: en el ejemplo el datos de valor 4 empuja la media hacia la izquierda, y la distorsiona en cierta medida, en perjuicio de su significado como medida de tendencia central, mientras que la media winsorizada proporciona un valor más ajustado al centro. Es por tanto, una medida robusta.